
Histoire
Psdc répond à un besoin. Celui d’automatiser la tâche fastidieuse de traduire des programmes entre différents langages de programmation.
Au cours de ma formation de BUT Informatique, j’ai appris l’algorithmie avec le Pseudocode, un pseudolangage de programmation inventé pour les besoins de l’IUT de Lannion. Inspiré du Pascal, le Pseudocode permet d’énoncer un algorithme dans un langage plus proche de celui de l’homme que de celui de l’ordinateur, tout en gardant l’aspect exhaustif de tout langage de programmation.
Au cours de nos TP, nous avons très souvent dû traduire des programmes en pseudocode vers le C. Cette tâche est assez réberbative, d’où mon désir de l’automatiser. Et c’est ce qui ma mené à découvrir la conception de compilateurs.
À titre d’exemple, voici un simple programme en pseudocode qui affiche Bonjour
à l’écran :
programme AfficherBonjour c'est début
écrireÉcran("Bonjour");
finVoici un programme équivalent en C :
#include <stdio.h>;
int main() {
printf("Bonjour\\n");
return 0;
}Comment automatiser cette transformation ? Et bien, en réalité, ce n’est pas si complexe. Le livre Crafting Interpreters[1] métaphorise le problème par l’ascension d’une montagne :
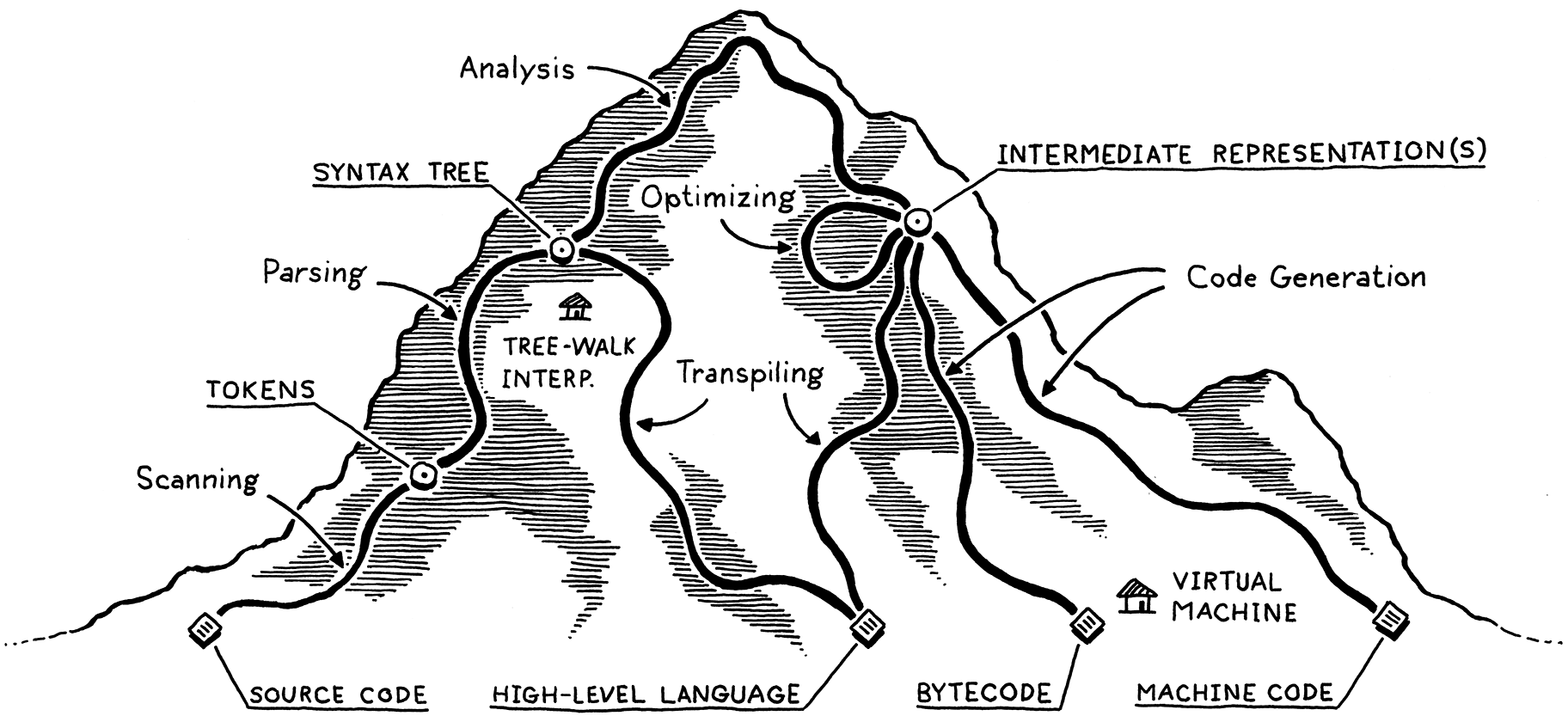
Commençons avec le code source original, au pied de la montagne. Au fil des étapes (scanning, parsing, analysis), la représentation du code devient de plus en plus haut niveau, c’est-à-dire qu’elle se focalise plus sur la sémantique exprimée que sur les détails d’implémentation.
Une fois le sommet atteint, on est à mi-chemin de la compilation. On a une vue imprenable sur la sémantique du code, soit le sens que l’utilisateur lui donne à travers la syntaxe de notre langage.
Alors entamons notre descente. Convertissons successivement notre représentation de haut niveau en des formes se rapprochant de notre objectif final : le langage machine, qui sera exécuté directement par le processeur.
Je n’ai découvert Crafting Interpreters qu’assez tard dans le projet. À l’origine, je me suis basé sur la playlist Creating a Compiler[2] de Pixeled sur YouTube, où l’on assiste à la conception et à l’implémentation d’un compilateur pour un language ex-nihilo nommé Hydrogen. Le compilateur transforme le code en assembleur, puis utilise NASM pour générer le code machine.
C’est dans ces vidéos que j’ai appris les bases de l’analyse lexicale[3], des grammaires formelles[4], ou encore de l’analyse syntaxique[5]. C’est vraiment intéressant et j’apprends beaucoup de choses.
Ce projet est loin d’être terminé — de nombreuses fonctionnalités restent à implémenter, notamment pour l’intégration VS Code avec serveur de langage.

